



推进下一代低延迟以太网

今天的人工智能应用是由大型语言模型(llm)驱动的,这些模型是在大量非结构化数据上训练的。llm的有效性与训练中使用的参数数量成正比。例如,GPT-3拥有1750亿个参数,而GPT-4预计将超过1万亿个参数。为了跟上人工智能性能的预期改进,预计LLM参数将每四个月翻一番。集群规模的计算是满足下一代人工智能指数级计算需求的必要条件,而在这个时代,更快的互联速率对于实现更高效的机架通信的重要性变得明显,需要下一代低延迟以太网。
从集群规模面,云厂商公开的资料显示目前亚马逊基于以太网的集群超过6万台服务器,Oracle超过3万台服务器,Meta超过2万台,字节超过1万台。这些超大集群网络都有部署基于以太网的后端网络。
从市场预测面,相关机构预测以太网的在RDMA板块的增速将逐步超越Infiniband,预计到2026年将获得比Infiniband更高的市场收入。
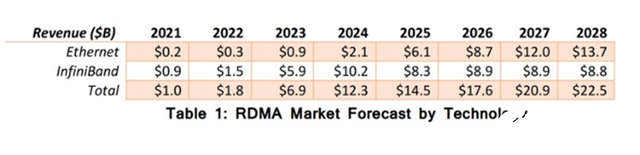
(Source: 650 Group)
从成本面,举个例子,Meta最新采用了基于InfiniBand网络的2.4万卡数据中心,总投资可达9.1亿美金,其中InfiniBand网络部分的成本就占了20%以上;单个交换机成本超过35000美金,总体交换机开销在接近7000万美金。
相比之下,采用了博通芯片的相关交换机售价仅为其一半不到。如果该数据中心采用以太网,Meta可以节省超过9100万美金。从云厂商/下游厂商的长期成本和性价比来看,随着以太网性能的持续提升以及其具备的普遍性和经济性,在满足整体算力需求及延迟性能的条件下,下游厂商未来使用以太网的意愿有望持续提升。
国内外 all In 以太网进阶赛
超级以太网联盟和SNIA主席J Metz表示:“在AI训练过程中,尾部延迟或者说组件间的通信速度,直接影响GPU的利用率。尾部延迟越低,计算资源的工作效率就越高。然而,将尾部延迟降至200纳秒以下——对这些应用程序和工作负载来说的理想水平并非PCIe和CXL等互连技术所能实现的。超级以太网的诞生将传统以太网推向了一个新的高度,使其准备好迎接需要超低延迟和高速度的新一代HPC和AI工作负载。”

2023年7月,超以太网联盟(Ultra Ethernet Consortium,简称UEC)成立,其中成员包括AMD、Arista、博通、思科、Meta和微软等,旨在解决以太网实际应用过程中的诸多不足。英伟达采取了以太网与IB并行的经营策略,其Spectrum-X解决方案同样基于以太网设计。据外媒消息,英伟达在今年7月份也加入了UEC ,有望助力推进其在以太网层面的产品及相关业务部署。
Nvidia is a member of the UEC because our strategy is to support networking specifications that can be beneficial to our customers. We may want to offer a UEC version of Ethernet in the future, alongside Spectrum-X and potentially other specifications in the future. (外媒原文)
超以太网联盟(UEC)将专注于为高性能人工智能优化和可扩展的完整的经济高效的以太网架构。为了实现其集成解决方案的使命,它成立了八个工作组:物理层、链路层、传输层、软件层、存储、管理、合规与测试、性能与调试。
下图简约说明了AI架构拓扑的一种类型,其中有几个不同的网络,每个网络都有不同的功能。前端是传统的以太网网络连接,而后端是向外扩展(UEC)网络。还有一个扩展网络连接cpu和xPU加速器。
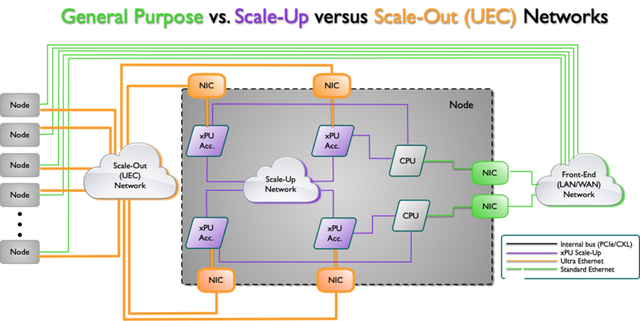
Source: Ultra Ethernet Consortium
从上图来看,Scale UP网络层面主要是通过xPU加速芯片片内及片间通信来完成,而Scale Out网络层面则重点指出了智能网卡与xPU加速芯片以及UEC网络间的通信。
国内生态以太网超节点项目在行动
近期,ODCC(开放数据中心委员会)网络工作组启动了ETH-X超节点系列项目。该项目由中国信通院、腾讯联合服务器厂商,交换机厂商、ODM厂商、芯片等上下游合作伙伴共同推动,以产品化样机以及相关技术规范为目标,打造大型多GPU互联算力集群系统。
ETH-X超节点项目提供了一种新的探索方向,旨在基于以太网技术,实现高带宽容量,构建一个开放且可扩展的Scale Up超节点体系。据ODCC披露,ETH-X超节点在训练和推理侧模型场景下,Scale up带来的性能(从通信数据速度和计算效率两大层面)提升远超过成本的增加并能够实现综合收益的提升。
交换机基于以太网的不俗表现
Scale Out网络从Tray to Tracy, Rack to Rack互联层面上来说,Leaf Switch 和 智能网卡NIC都是非常关键的互联组件。在 Datacenter 规模扩大过程中,服务器数量的增加以及集群更高带宽更低延迟的通信需求一定会带来智能网卡和Leaf Switch 的需求增长。
Leaf Switch是一种机架级交换机,主要用于将同一机架内的多台服务器通过高速网络互联起来。它可以与服务器的网卡对接,从而组成机架内部的高速网络。在以太网层面,交换机领军厂商Arista 以及数据中心多方案解决方案提供商Broadcom就是具有代表性的企业。
交换机行业巨头Arista Network在一次财报电话会议上披露,该公司与Broadcom合作开发的AI集群,基于Arista以太网产品的运行速度至少比英伟达的InfiniBand快了10%。而且Arista的以太网产品在Meta今年三月推出的两个超大规模算力集群中,性能完全不逊色于Infiniband。此外,Arista预计到2025年能够连接1万到10万个GPU。

博通在数据中心领域具有更强势的地位,其产品线覆盖交换机、Xpu加速芯片、高速光模块等。博通也是最早首发光模块CPO形态样机的一家公司。该公司在24年6月举行的FY24 Q2业绩会上宣称目前八个最大的GPU集群当中,有七个使用以太网,并且博通认为25年所有的超大规模集群都将采用以太网组网;
在产品方面,随着集群网络对于智能网卡速率要求往400G及以上不断演进,博通在上半年发布了最新的高可扩展,高性能,低功耗400G PCIe Gen 5.0以太网网卡产品组合。以解决人工智能数据中心中XPU带宽和集群规模快速增长时的连接瓶颈。

奇异摩尔:基于以太网RoCE v2 RDMA的全栈互联架构解决方案
在网络互联层面的互联架构产品解决方案均基于以太网RDMA RoCE V2,相比私有协议和网络,具有更开源的软硬件兼容性。
我们的互联架构解决方案同时可覆盖Scale Up & Scale Out网络扩展方案,全面加速服务器集群互联通信。
目前800Gps以太网已经实现商用部署,1.6Tbps以太网有望在2025年实现成熟商用。在服务器集群与GPU卡间互联侧,奇异摩尔AI原生智能网卡SmartNIC(高达800G速率)与网络互联加速芯粒系列均基于以太网RDMA 技术构建,更符合国内智算中心主流的软硬件系统搭建,满足集群间/GPU卡间高速通信需求。
奇异摩尔的Die2Die IP 基于UCIeV 1.1国际标准协议,提供32 Gbp可作为第三方独立IP,兼容各家产品的互联互通。同时我们也是国内为数不多布局Central I/O Die 互联芯粒的厂商并已成功实现流片(如AMD基于CPU内建 I/O die)。I/O Die 系列产品包括2.5D/3D 互联芯粒,通过UCIe V 1.1 D2D形成片内不同模块的互联,支持各类互联接口,皆在赋能国内芯片企业制造出更高算力、更高性能的芯片。
写在最后,未来的超大规模网络是基于以太网还是Infiniband,又或是并存的一种网络生态。正如AMD 苏妈所坚持的,“行业没有一种万能的解决方案,因此模块化和开放性将允许整个生态系统在他们想要创新的地方进行创新。”无论是UEC,还是UCIe 标准,未来可预见的是更多标准与生态的出现。半导体行业正是这样一个引领科技创新的产业,在不断的技术应用探索中,推动现代科技的发展,为人类社会带来变革。

服务热线:
4007654355